Network DataBase (NDB)
MySQL Cluster – система распределенного хранения данных в рамках СУБД MySQL, решение для построения отказоустойчивых систем.
Поскольку Оракл, выкупивший MySQL в своё время, не предоставляет функциональности NDB по умолчанию, проверим её наличие:
Проверка поддержки NDB
mysql> SELECT VERSION()\G
*************************** 1. row ***************************
VERSION(): 5.6.27-ndb-7.4.9
1 row in set (0.00 sec)
Три основных типа нод
Картинка из штатного MySQL Cluster Overview
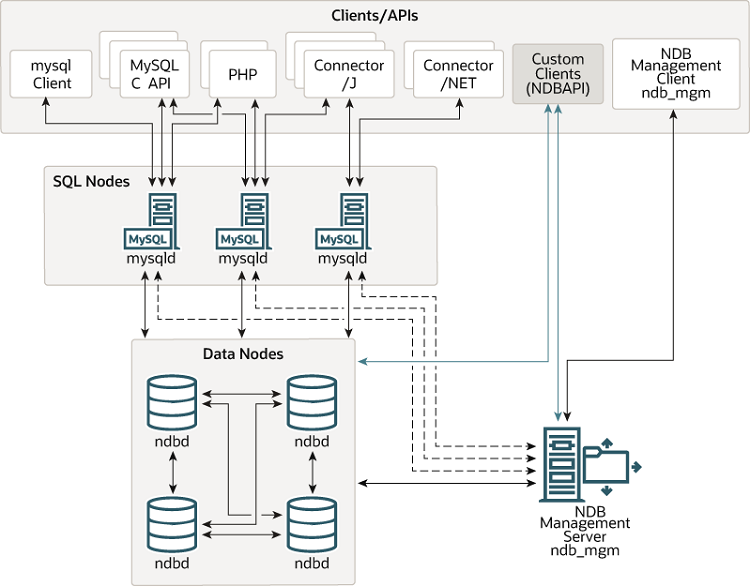
Понятие нода (узел) в контекстке MySQL NDB Cluster
Нодой называется не физический сервер, выполняющий тот либо иной процесс MySQL, а менно сам процесс MySQL/NDB.
Дата-нода (ndb-нода)
Исполняемый процесс ndbd, отвечающий за хранение фрагмента данных в кластере.
Важный параметр кластера NoOfReplicas (число реплик) - число дата-нод на которых хранится каждый конкретный фрагмент. Общее число дата-нод должно быть кратно числу реплик.
Группа нод - несколько нод (число нод в группе равно числу реплик), хранящих идентичную информацию.
Например
NoOfReplicas = 2, число нод - 6.
Каждая таблица разбита на 6 фрагментов (по хэшу первичного ключа), пронумеруем их F1,F2,F3,F4,F5,F6.
6 нод (D1,D2,D3,D4,D5,D6) составляют 3 группы:
- каждая нода первой группы (D1,D2) хранит фрагменты F1,F2
- ноды второй группы D3,D4 хранят фрагменты F3,F4
- ноды третьей группы D5,D6 хранят фрагменты F5,F6
Выход из строя всех нод одной группы приводит к отказу кластера.
SQL-нода (или API-нода)
Исполняемый процесс mysqld.
SQL-нода принимает подключение клиентов и обращается к дата-нодам за данными. Кроме того, каждая SQL-нода вправе хранить собственные не-NDB таблицы (MyISAM, Innodb, ...), как если бы она не входила в кластер.
Управляющая нода (management-нода)
Исполняемый процесс ndbmgmd. Отвечает за конфигурацию кластера, каждая нода обращается к управляющей ноде при подключению к кластеру.
Не управляет транзакциями и другими текущими делами, а концентрируется исключительно на конфигурации.
Потребляет немного системных ресурсов, поэтому часто размещается на одном же физическом сервере с другой нодой.
В случае выхода из строя управляющей ноды, кластер продолжит нормальную работу, но будет невозможен перезапуск нод.
Конфигурация может содержать одну или несколько управляющих нод.
Арбитр и алгортимы арбитража
Арбитр
Одна из нод кластера всегда является арбитром.
Арбитр назначается при запуске кластера и может изменяться в рамках процедуры смены арбитра.
О назначении и смене арбитра можно узнать в логах кластера.
В конфигурации по-умолчанию, арбитром является управляющая нода, однако это не обязательно так.
Арбитром может стать любая управляющая или SQL-нода. У этих нод в конфигурации может быть указан параметр ArbitrationRank (ранг арбитра); значения параметра следующие:
0 - нода никогда не станет арбитром
1 - нода станет арбитром с высоким приоритетом
2 - нода станет арбитром только если нет претендентов с высоким приоритетом
В каждый момент в кластере только один арбитр.
Отключение группы нод, split-brain
Арбитр требуется в ситуации, когда от кластера отключились несколько нод.
Пусть кластер физически разделился на 2 кусочка (например, в силу отказа сетевого маршрутиризатора). Возможна ситуация, когда каждый кусочек будет хранить все данные кластера (то есть по крайней мере по одной ноде из каждой группы). Каждый кусочек будет вести себя как полный кластер, что приведет к нарушению целостности данных (например, часть клиентов будет работать с одним кусочком, а часть - с другим).
Такая ситуация потенциально опасна и называется split-brain.
Алгоритм арбитража
Алгоритм арбитража достаточно простой. Он начинает работу сразу после обнаружения фрагментации на каждой работающей дата-ноде осколка кластера.
Вижу ли я по крайней мере одну дата-ноду из каждой группы (иначе говоря - обладает ли видимая часть кластера всеми данными)? Если нет - выключиться. Если да, продолжить алгоритм
Есть ли среди отключившихся дата-нод по одной из ноде из каждой группы (иначе говоря - обладает ли вторая часть всеми данными)? Если нет - значит вторая часть выключится по правилу 1, я могу продолжить работу. Если да, продолжить алгоритм.
Спросить арбитра. Если арбитр недоступен - выключиться. Если арбитр доступен, узнать присутствую ли я в текущей конфигурации, если нет - выключиться, если да - продолжить работу Смена арбитра
Если в результате фрагментации исчез арбитр, то после выполнения алгоритма арбитража, ноды выбирают нового арбитра. Алгоритм выбора в настоящее время простой - выбирается нода с наименьшим номером (nodeid), среди имеющих старший ArbitrationRank.
Примеры
Почему конфигурация из двух физических не является оказоустойчивой?
Рассмотрим следующую конфигурацию, постоенную на двух физических машинах:
Первый сервер - дата-нода 1, SQL-нода 1, управляющая нода 1
Второй сервер - дата-нода 2, SQL-нода 2, (возможно также управляющая нода 2)
Значение NoOfReplicas=2 обеспечивает дублирование данных; обе ноды входят в одну группу. На первый взгляд кажется, что конфигурация откзоустойчива, но на практике это не так. При старте кластера арбитром станет первая управляющая нода. Рассмотрим ситуацию, в которой вышел из строя первый сервер (например выключился, сгорела сетевая карта или вышел из строя порт в маршрутиризаторе). На второй дата-ноде сработает алгоритм арбитража:
Вижу ли по одной ноде из каждой группы? Да, всего одна группа, эта нода - я. Содержит ли отключивашаяся часть полный набор данных? Да, дата-нода 1 содержит копию данных. Спросить арбитра. Арбитр недоступен. Выключиться. Мы видим, что отказ одного сервера приводит к отключению всего кластера.
То же самое произойдет в конфигурации с тремя серверами и NoOfReplicas=3 при отключении сервера, содержащего арбитра.
Простой пример отказоустойчивой конфигурации
Предоставим читателю убедиться в том, что следующая конфигурация является устойчивой по отношению к отказу любого из трех физических серверов:
Первый сервер - дата-нода 1, SQL-нода 1 (ArbitrationRank=0), (NoOfReplicas=2)
Второй сервер - дата-нода 2, SQL-нода 2 (ArbitrationRank=0), (NoOfReplicas=2)
Третий сервер - управляющая нода (ArbitrationRank=2)
К вопросу о тестировании
Избыточность данных еще не гарантирует отказоустойчивость. Обязательно тестируйте конфигурации с использованием описанного выше аглоритма, путем отключения сетевых интерфейсов или путем физического отключения серверов.
К вопросу о производительности
Краткие тезисы:
- Таблицы хранятся по нодам построчно (по ключу auto_increment).
- Данные дублируются на нескольких нодах одновременно
- Индексы тоже хранятся на нодах в виде таблиц со всеми вытекающими: распределение между нодами построчно.
Что вытекает из этого? Что бы выполнить полноценный запрос sql с JOIN или несколькими условиями будут выполнены следующие действия:
- по ключу будет найдена нода, хранящая доп. условие;
- на данной ноде будет найдена необходимая запись.
И это для каждого условия, так как разные индексы одной записи могут оказаться на разных нодах.
То есть при одном дополнительном условии (к поиску по автоинкрементному ключу) будет выполнено вместо одного запроса три. При двух дополнительных условиях — пять запросов и т.д.
Производительность кластера из 4-х нод примерно соответствует одному классическому серверу MySQL.
engine_condition_pushdown
ndbcluster более чувствителен к качеству запросов, причём работает несколько факторов
Оптимизатор в MySQL общий, и он может учесть не все факторы, важные для движка ndb.
Ошибки оптимизации обходятся дороже. Например, запрос
SELECT * FROM table_name WHERE x>y*y;
в innodb выполнится путем перебора всех записей на диске. В ndb необходимо будет еще передать все записи на API-ноду, и только на ней обработать.
В mysql начиная с версии 5.0.3 дата-ноды могут выполнять простую арифметику, это называется "push down conditon", но это только при engine_condition_pushdown=1 и только для простых операций (функции mysql, такие как md5() или sin() на ноды не переносятся).